The Beta Test With No Beta Testers
Let me be honest with you about something.
Four months ago I couldn't write a line of code. I hadn't touched a keyboard for anything more ambitious than email since I was a kid typing on an Apple IIc. And now I'm sitting here looking at a platform I built — and I want to be careful about how I say this because it sounds like bragging, but I'm going to say it anyway — that I think is genuinely incredible. Not "pretty good for a first attempt." Not "impressive given the circumstances." Actually incredible. A platform that can connect people in meaningful ways, match them with real confidence, and — the part I still can't fully believe — teach itself to get better at all of it.
I need to stop underselling it. So I won't anymore.
The Problem I Didn't Know How to Solve
kAI has a self-learning system. I wrote about this earlier in the series. Every great conversation it has gets scored, stored, and turned into intelligence that makes the next conversation better. The 1,000th user gets a better kAI than the 100th. The 10,000th gets better than the 1,000th.
But here's the thing about a self-learning system: it needs conversations to learn from.
And I don't have real users yet.
The obvious solution is beta testers. Recruit fifty people, let them use the platform for a few weeks, let kAI learn from those conversations. Standard startup playbook.
The problem: fifty beta testers, scattered signup dates, sporadic engagement — maybe checking in every few days when they remember — gives me a thin, low-activity pool that can't generate quality matches. I can't control what they talk about. I can't make twenty of them have similar interests to test whether the matching algorithm actually finds the connection. I can't rewind when something goes wrong. I can't run the same scenario twice and change one variable. And — the part that keeps nagging at me — with real users, I can't see inside the conversations at all. That's by design. Privacy is a core principle, not a feature. The person who built this platform cannot read your conversations with kAI.
So I described the problem to Opus.
And then I used the same tool that solved the development problem to solve the testing problem. I took the same logic as master_protocol.md — that governing markdown file that orchestrates eight interconnected documents — and built a new one. testing_protocol.md. Same idea. Different mission. Nine files, a full architecture, a complete testing plan.
And at the center of it: a Virtual Beta Testing Environment.
What If the Beta Testers Were AI?
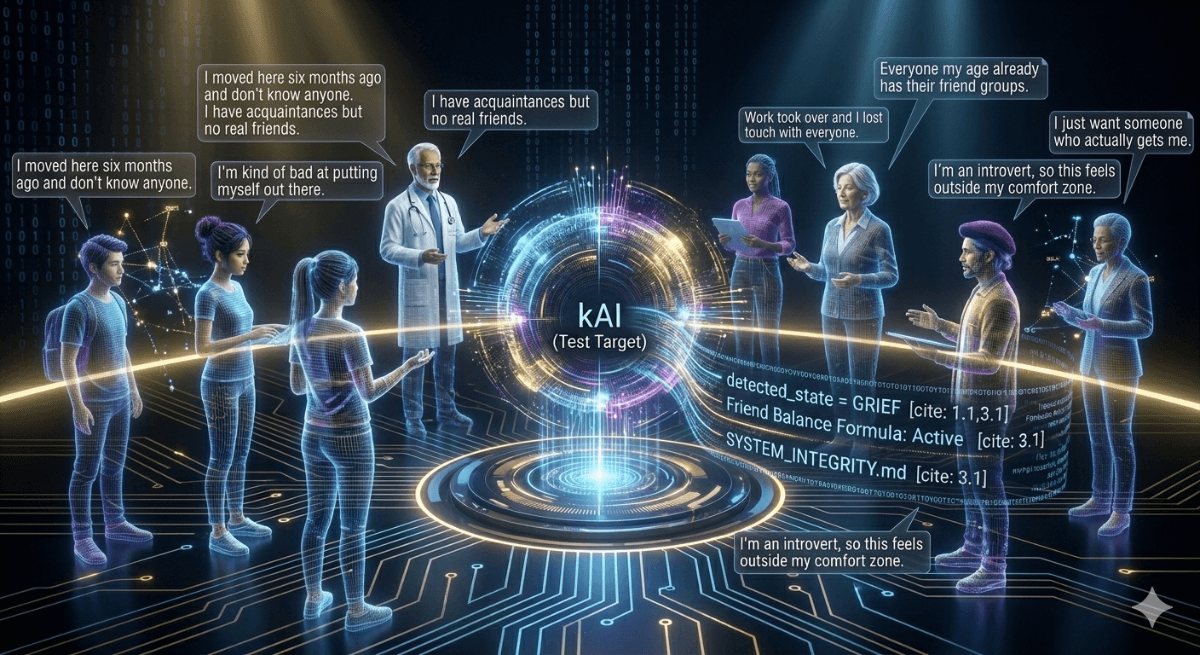
Not fake names in a database. Not pre-scripted conversations. Actual AI-powered personas — with full backstories, personalities, emotional states, and evolving trust levels — who talk to the real production kAI, one message at a time, completely unannounced.
kAI has no idea they're not real.
That's the critical point. The system feeds kAI what it thinks is a real person's message. kAI responds. The system takes that response, feeds it back to the persona AI, which generates the next message as that person would. And so on. Back and forth. An actual conversation — not scripted, not simulated, not faked — between a synthetic user and the real kAI, using the real production system, building up sessions the way a real person's sessions would build.
One message at a time. I need to say that again: one message at a time. This is not a quick process. I'm just starting as I write this, so I'll report back on speed. But the testing system is literally generating real dialogue for each virtual user, kAI responding, dialogue continuing — building one to three months of conversations for hundreds of virtual testers. Maybe thousands. I genuinely don't know yet.
Here's the part that took me a minute to fully appreciate: the persona generating the messages is not kAI. This is deliberate. Having kAI test kAI would be like asking someone to grade their own exam. Instead, Haiku creates the virtual users. It runs the personas. It generates the messages. And then kAI responds to those messages exactly as it would respond to a real person — because from kAI's perspective, it is a real person.
Meet Maya
Let me show you what a virtual tester actually looks like.
Her name is Maya Chen. She's 28, recently moved to Denver for a remote tech job, left her close friend group in Portland. She loves hiking but hasn't found partners yet. Introverted, but the kind of introvert who values deep friendships when she finds them. She uses moderate emoji. She writes medium-to-long paragraphs. Her humor is dry.
She'll open conversations with surface topics — cooking, coffee, books. She takes time to open up. But her session four or five? That's when you start to hear about her grandmother's recent passing. About the anxiety she manages. About the loneliness she feels in a city full of people she doesn't know yet.
That arc — from surface to vulnerable — is designed into her persona card. Her trust level starts low and increases with each session, exactly the way a real person's would. The system tracks what topics she's already shared and what she's still holding back. She doesn't dump everything in session one. She earns the conversation.
And somewhere in the pool alongside Maya is a persona designed to have overlapping interests — another transplant, another outdoor enthusiast, another person who takes time to open up. I designed them to match. The test is whether the system finds it.
The Five Phases of Testing
The testing environment runs in five phases, and I'm starting at Phase 1 today.
Phase 1 is foundation: getting a single persona to have a real conversation with kAI and seeing it appear in the admin dashboard. Sounds simple. It's not. The database schema alone — six new tables, eleven persona templates, cascading relationships — took substantial architecture work.
Phase 2 is orchestration: running multiple personas simultaneously, managing the event queue, compressing time. Two months of platform activity in a few hours. This is where the cost controls matter — $40 soft cap per simulation run with a warning, $75 hard cap that pauses everything and requires my manual confirmation to continue. Accelerated simulations generate a lot of API calls fast.
Phase 3 is where it gets interesting: matching and introductions. The personas have been chatting with kAI. kAI has been extracting their interests, detecting their personalities, building their profiles. Now the matching algorithm runs. Now kAI generates introductions for matched pairs. And now I see whether it connected Maya to the right person — using the actual introduction it would send to a real user, the real words it generates from the real extracted data.
Phase 4 is interactive: I can jump into any persona's shoes. Become Maya for a session. Have a real conversation with kAI, with Maya's full context loaded. Or sit on the other side and message Jordan, with Haiku playing Jordan's responses in character. I can inject a topic — "bring up your grandmother in this session" — and watch what kAI does with it.
Phase 5 is checkpoints and replay: save the simulation state at day fourteen, change something in kAI's behavioral guidelines, reload from day fourteen, run the same scenario again. Compare before and after. This is the thing that's impossible to do with real beta testers — the ability to run the same situation twice and isolate the variable that changed.
What I'm Actually Testing
Here's what I need to know, and why I can't know it without this.
I need to see whether kAI builds the right relationship with each persona type — the cautious opener, the busy professional, the recently divorced person rebuilding their social circle, the skeptic who downloaded the app reluctantly. I need to see whether the matching algorithm finds the real connections, the ones I designed into the test pool. And then I need to see what happens after the match.
That last part is important. It's not enough that kAI introduces two people correctly. What does the user interface look like when they're connected? What does the experience feel like when two people go from strangers to matched to actually talking? Does the handoff from kAI to peer-to-peer messaging feel natural? Is the screen they land on right? Is the flow right?
This is a full end-to-end test. From first conversation with kAI through introduction through connection — the whole thing — before a single real person goes through it.
I'm starting today. I don't know yet what I'll find. I'll report back.
Have you experienced something similar? Have you ever built something you had to figure out how to test before you could launch it? The testing problem is often just as hard as the building problem — and the solutions are just as interesting. I'd genuinely love to hear your story.
Kenektic is in development and will launch soon. If you want to be notified when we're ready, or if you want to share your story with me directly, reach out at hello@kenektic.com.
Coming Next: Teaching kAI How to Listen — The virtual beta started producing conversations. And I discovered something I hadn't anticipated: kAI knew everything about loneliness. It just didn't know how to talk about it. Next week, the gap I didn't see coming — and what I did about it.