Claude Opus 4.7: When the PhD Brought a Team
Special Edition Mid-week Post. The regular weekly series continues Monday with Post 27.
On April 13th, I ran a complete code review of Kenektic using Claude Opus 4.6.
It was thorough. Detailed. The kind of analysis I wrote about in February, when Opus 4.6 first arrived and found eleven vulnerabilities that Opus 4.5 had missed only twenty-four hours earlier. That post, if you read it, was about watching a model upgrade not just do the same work faster but do work that was qualitatively different. The PhD got smarter, I said at the time.
I finished the April 13th review feeling good. Grade of A-minus. Zero critical findings. Three high findings I already understood. A platform ready for university deployment with conditions I could address in a week.
Three days later, on April 16th, Anthropic released Claude Opus 4.7.
I ran the same review again.
It found four new critical issues and roughly a dozen new high-severity findings. Opus 4.6, just seventy-two hours earlier, had missed every one of them.
What Was Different
Let me be general about the specifics because the details are proprietary, but the categories matter.
Two of the new criticals were configuration problems. The kind of issue where a build setting in one file is silently ignored by a tool configured in another file, meaning the protection you think you have is not actually active in production. Opus 4.6 had run the build, seen it pass, and moved on. Opus 4.7 traced the configuration through three different files and noticed that one of them was shouting at the others without being heard.
A third critical was an authentication gap on an admin endpoint. Opus 4.6 had noted in passing that "two admin routes have unverified auth patterns" as part of a security score deduction. That was accurate but vague. Opus 4.7 named the specific route, identified the specific line of code, explained exactly what information would leak, and elevated it to critical. Same raw observation, totally different level of specificity and urgency.
The fourth critical was a directory of archived code sitting in the repository that should have been deleted months ago. Not a security issue in itself, but a due-diligence red flag, a context pollutant for every AI tool that reads the repo, and more than a megabyte of dead weight in every deploy. Opus 4.6 had not flagged it at all. Opus 4.7 found it and explained why it mattered.
The new high-severity findings followed a similar pattern. A security patch for Next.js that was released after my April 13th review. Missing database indexes on three tables that get queried on hot paths. A pattern of inefficient database calls that had been marked resolved in one file but were present across many others. An error-handling framework that had been implemented well but adopted by only half the routes that should use it.
None of these are disasters. Most are a few hours of focused work. Taken together, they represent something meaningful about where Opus 4.6 had been right and where it had been shallow.
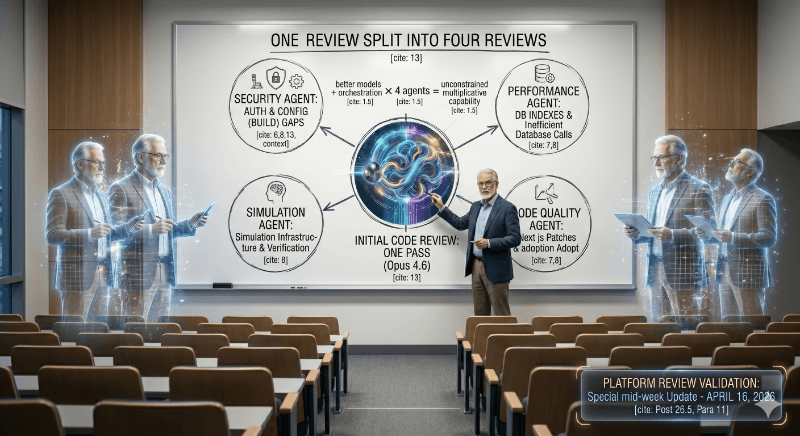
The Four Agents
Here is what Opus 4.7 did that 4.6 did not. It ran four agents in parallel.
I did not ask for that. I asked the same question I had asked three days earlier. Opus 4.7 decided, on its own, to spin up four specialist sub-agents simultaneously. One for security and authentication. One for performance and database. One for simulation infrastructure. One for code quality and architectural bloat.
Each agent went deep in its own domain. Opus 4.7 then synthesized the results into a single coherent review.
Opus 4.6 ran one pass. Opus 4.7 ran four passes in parallel and reconciled the output.
The difference is not subtle. It is the engineering equivalent of swapping out a single senior reviewer for a full audit committee, each with a specialty, each reporting back to a staff engineer who integrates the findings. Except it happened in about fifteen minutes and cost less than lunch.
One more thing worth mentioning. Opus 4.7 also confirmed that a major feature I had built, which Opus 4.6 had mis-categorized as "not started," was actually complete and verified. So it was not just finding problems I did not know about. It was recognizing work I had done that the previous model had missed.
Compared to Moore's Law
In February I wrote a full post about Moore's Law. The short version: chip transistor counts doubled every eighteen to twenty-four months, and that pace held for fifty straight years. Each cycle delivered something genuinely new. Each cycle was also considered fast at the time.
Seventy-one days passed between Opus 4.6 and Opus 4.7. Not a minor patch. A real capability jump. If chips had advanced at this pace, the entire decade of the 1990s, the rise of the PC, the birth of the commercial internet, would have compressed into a single year.
AI is not going to stay on this curve forever. Nothing ever does. But right now, the comparison is impossible to miss.
What This Keeps Teaching Me
I am going to say something that might sound dramatic, but I mean it literally.
The platform I built on Monday is being reviewed on Thursday by a fundamentally more capable intelligence than the one that reviewed it Monday morning. That is not a figure of speech. The gap between Opus 4.5 and Opus 4.6 was the gap between a brilliant senior engineer and that same engineer after graduate school. The gap between 4.6 and 4.7 is the gap between one senior engineer and a coordinated team of four specialists.
Three days. One release cycle. And the platform I am building is measurably safer, better understood, and more thoroughly audited because the review model got smarter while I slept.
I have stopped being surprised by this. I have started to expect it.
Which is, I think, the thing I should have expected least of all.
Have you experienced something similar? Have you ever had a tool improve under you so quickly that the earlier version of your work keeps getting revised by smarter and smarter readers? I'd genuinely love to hear your story.
Kenektic is in development and will launch soon. If you want to be notified when we're ready, or if you want to share your story with me directly, reach out at hello@kenektic.com.
Coming Next: I Read Nine Books So kAI Wouldn't Have To. There's a difference between knowing about loneliness and knowing how to be present with someone experiencing it. The research library taught kAI the first. Nine books on how humans actually talk to each other taught it the second. Next week: the specific books, the techniques I pulled out of them, and how it all ended up baked into kAI's brain.